The Enterprise AI Spectrum: A Systematic Approach to Durable ROI
Why organizations achieve lasting AI value by climbing an autonomy ladder incrementally—proving value at each level before advancing—rather than leaping to high-agency systems that outpace their governance maturity.
📚 Want the complete ebook version?
Sarah’s team deployed an AI agent that processed 99 insurance claims perfectly. One claim contained an error—a minor field misclassification that would have been caught in downstream review.
But the CEO heard about it the next morning. By afternoon, six months of AI development work was canceled.
This story—or variations of it—plays out across enterprises every week. But it’s not a failure of technology. It’s a maturity mismatch: deploying a Level 7 system (autonomous multi-step agents) with Level 2 governance (basic testing and human review).
The agent had no observability stack, no regression testing suite, no error budget, no incident playbook. One visible mistake in 99 successes generated enough political backlash to kill the entire initiative.
If you’ve witnessed this pattern—or fear you’re about to—this guide explains why it happens and how to avoid it by systematically climbing an AI autonomy spectrum.
The Hidden Epidemic: Why 70-95% of Enterprise AI Projects Fail
Gartner predicts that 60% of organizations will fail to realize AI value by 2027 due to incohesive governance. And by end of 2025, they expect 30% of generative AI projects to be abandoned after proof-of-concept.
These aren’t minor setbacks. They represent billions in wasted investment and mounting organizational AI disillusionment.
The Real Root Cause: It’s Not the Algorithms
RAND Corporation analyzed 65 data scientists and engineers to identify five root causes of AI project failure:
- Problem misunderstanding: Stakeholders miscommunicate what problem needs solving
- Inadequate data: Organizations lack data to train effective models
- Technology focus over problem-solving: Chasing latest tech vs. solving real problems
- Infrastructure gaps: Inadequate infrastructure to manage data and deploy models
- Problem difficulty: Technology applied to problems too difficult for current AI
But here’s the critical insight from BCG’s 2024 research:
Organizations deploy ambitious autonomous agents without the organizational scaffolding to manage them:
- 75% have AI usage policies, but less than 60% have dedicated governance roles or incident playbooks
- Most violate the 70-20-10 rule: Successful AI governance allocates 70% effort to change management and organizational readiness, 20% to data infrastructure, and only 10% to algorithms. Most organizations invert this ratio.
- Less than 40% of senior leaders understand how AI technology creates value
- Over 80% report no tangible EBIT impact at enterprise level despite GenAI adoption
The pattern is clear: organizations treat AI deployment as binary—chatbot or autonomous agent—when there’s actually a spectrum of seven autonomy levels, each requiring fundamentally different governance maturity.
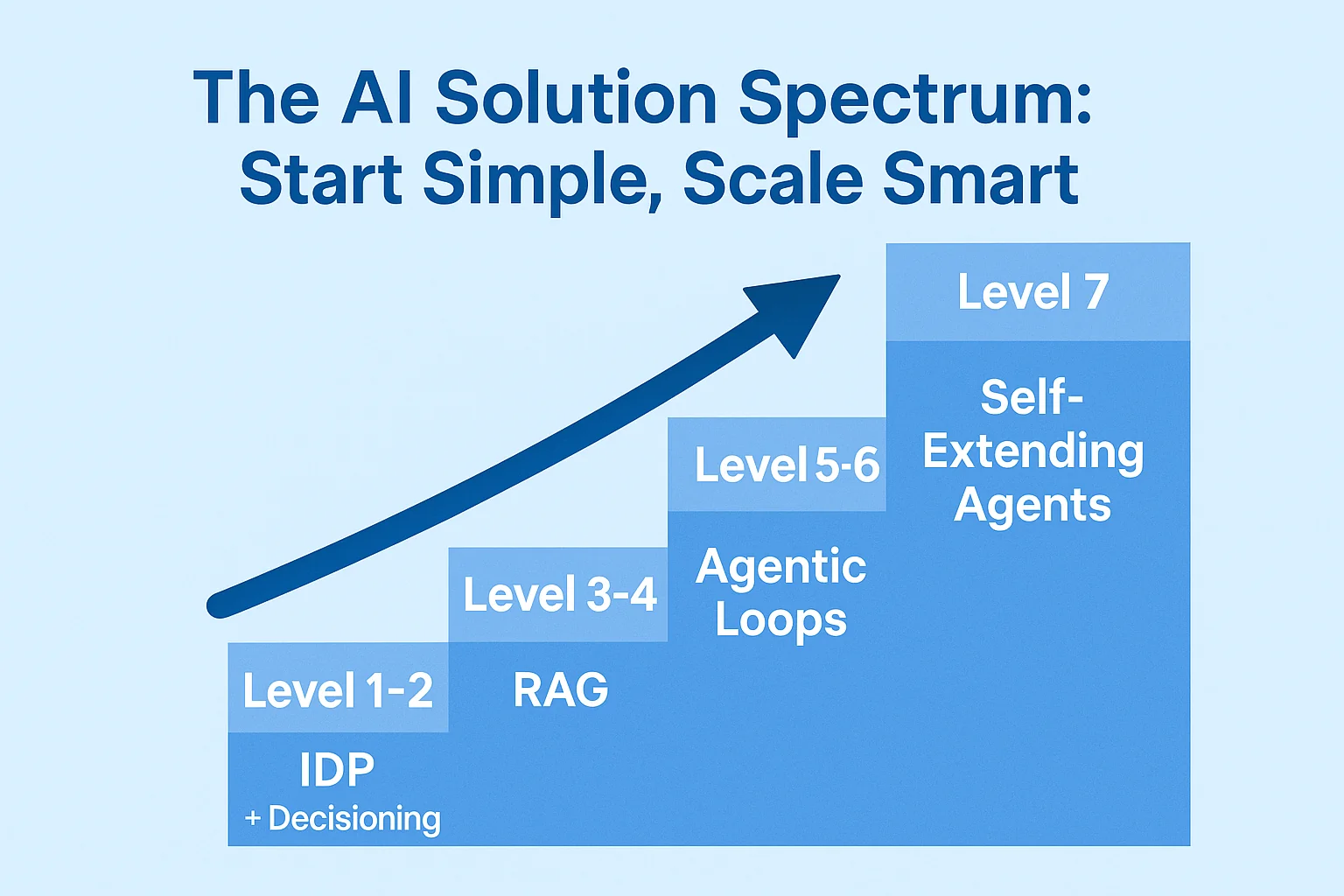
The Enterprise AI Spectrum: 7 Levels from Deterministic to Self-Extending
Every major framework—Gartner’s AI Maturity Model, MITRE, MIT CISR, Deloitte—converges on the same fundamental pattern: incremental progression from simple automation to autonomous systems.
And critically, every major cloud provider (AWS, Google Cloud, Azure) publishes reference architectures that follow this exact sequence. This isn’t theory—it’s the documented path from industry leaders.
Here’s the spectrum and what each level requires before you can safely advance:
Intelligent Document Processing (IDP) + Simple Decisioning
What it does: AI reads documents (invoices, emails, PDFs, forms), extracts structured data, and prepares records for human review. Or it classifies and routes work items (fraud triage, support queue assignment, document categorization).
Technical architecture:
- Serverless, event-driven pipeline: ingest → extract → classify → enrich → validate → store
- Services: OCR (Amazon Textract, Azure AI Document Intelligence), NLP (Amazon Comprehend), human review (Amazon A2I), workflow orchestration (AWS Step Functions, Azure Durable Functions)
- Infrastructure as code deployment
Governance requirements before advancing:
- Human review UI with approval workflows
- Extraction accuracy metrics (F1 score ≥90%, precision, recall by field type)
- Sample-based testing on diverse document types
- Process documentation and runbooks
- Basic cost tracking per document processed
When to advance: Extraction accuracy >90%, human review process working smoothly, team comfortable debugging extraction failures, documented baseline human error rate for comparison.
Typical use-cases: Invoice/PO processing → ERP, claims intake, order entry from email, contract data extraction, document classification and routing, form processing.
Market adoption: 60%+ of Fortune 250 companies use IDP tools. Benefits include 35% cost savings and 17% reduction in document-related work.
Retrieval-Augmented Generation (RAG) + Tool-Calling Assistants
What it does: AI searches your organization’s trusted knowledge base, retrieves relevant passages, and generates answers with citations. Or it selects and invokes predefined functions (CRM.read, CreateTicket, GetPrice, UpdateStatus)—keeping business logic in your code, not prompts.
Technical architecture (RAG):
- Three-stage pipeline: (1) Retrieval: query → vector embedding → similarity search in vector DB, (2) Augmentation: relevant docs added to context via prompt engineering, (3) Generation: LLM generates answer grounded in retrieved context
- Services: Vector databases (Amazon OpenSearch, AlloyDB with pgvector, Azure Cosmos DB), embedding models (Amazon Bedrock, Vertex AI), LLM APIs
- Connectors to data sources, preprocessing pipelines, guardrails for accuracy and hallucination prevention
Technical architecture (Tool-Calling):
- LLM constructs calls to external tools (via function calling / tool use APIs)
- Separate execution layer runs the tool and returns results
- Supports chaining: LLM reasons between tool calls, enabling sophisticated multi-tool workflows
Governance requirements before advancing:
- Eval harness: 20-200 test scenarios covering edge cases, auto-run on every prompt/model change
- Regression testing: CI/CD pipeline that catches when fixing one scenario breaks others (prevents “fixed one, broke 22%” problem)
- Citation and audit trails: Which documents influenced this answer? Traceable back to source.
- Version control: Prompts, configs, tool definitions tracked in git with code review
- RAG-specific metrics: Faithfulness (>85%), answer relevancy, contextual precision/recall, retrieval precision@k
- Tool-calling constraints: Read-only or reversible actions only at this level
When to advance: RAG faithfulness >85%, no hallucinations in eval suite, tool calls auditable and reversible, rollback mechanisms tested, team can debug retrieval failures and prompt regressions.
Typical use-cases: Internal policy Q&A with citations, technical documentation search, CRM data lookup assistants, contract review assistants, compliance query systems, draft generation (emails, reports) with source attribution.
Libraries and frameworks: LlamaIndex (optimized for RAG, 2-5x faster retrieval), LangChain (broader flexibility for complex workflows), RAGAS (evaluation framework), OpenTelemetry for tracing.
Agentic Loops: ReAct Pattern + Multi-Agent Orchestration
What it does: AI iterates through Thought → Action → Observation cycles until a multi-step goal is met. Workflows span multiple systems. Example: “Close this support ticket—read customer context, check entitlement in billing system, draft fix using knowledge base, schedule follow-up in CRM, file resolution notes.”
Technical architecture:
- ReAct loop: (1) Thought: verbalized chain-of-thought reasoning decomposes task, (2) Action: executes tool/API call, (3) Observation: evaluates progress, informs next thought. Repeats until solution or stop condition.
- Multi-agent patterns: Supervisor (centralized coordinator delegates to subagents), Sequential (chain agents in predefined order), Adaptive (decentralized peer collaboration)
- Orchestration: LangGraph (graph-based workflows), AWS Step Functions, Azure Durable Functions, custom state machines
- Critical infrastructure: Full observability stack, guardrails framework, budget controls, incident automation
Governance requirements before advancing:
- Per-run telemetry: Capture inputs, retrieved context, model+prompt versions, every tool call with parameters, token/cost, final output, any human edits. Enables case lookup for audits and disputes.
- Guardrails: Input validation (prompt injection defenses, PII redaction), output filtering (policy checks, toxicity detection), runtime safety (budget caps, rate limiting, max iterations)
- Rollback mechanisms: Ability to undo multi-step operations or compensate for partial failures
- Kill-switch capability: Instant halt for runaway agents or unexpected behavior
- Incident playbooks: Severity levels (SEV1: policy/PII violation = immediate rollback; SEV2: workflow error = auto-escalate; SEV3: harmless inaccuracy = log and continue)
- Canary deployments: Feature flags for gradual rollout, instant rollback on error spike
- Error budgets: Define acceptable failure rates by impact category, monitor burn rate
When to advance: Error rate within budget (<1% for irreversible actions), incident response rehearsed and fast, team can debug multi-agent failures using telemetry, observability allows case lookup in <2 minutes, change failure rate <15%.
Typical use-cases: Multi-system research and compilation tasks, automated triage and routing with context gathering, complex approval workflows, data reconciliation across systems, intelligent workflow automation.
Enterprise platforms: Amazon Bedrock AgentCore (serverless runtime, session isolation, DynamoDB state), Google Cloud Agent Builder (ADK, Agent Engine, Memory Bank), Azure multi-agent orchestration patterns.
Critical consideration: Token usage varies by 200%+ depending on reasoning iterations and coordination complexity. Budget accordingly.
Self-Extending Agents: Learning New Tools and Skills
What it does: AI learns new capabilities over time—writing new parsing functions when it encounters unfamiliar document types, discovering and integrating new APIs, building a skill library that expands as it encounters new problem patterns. The agent modifies its own toolset.
Technical architecture:
- Agent writes code (scripts, SQL, API wrappers) to solve tasks outside its fixed toolset
- Sandboxed execution environment (containers, VMs) for generated code
- Skill library with versioning and rollback
- Code review and approval gates before promotion to production
- Enhanced monitoring for unexpected behaviors, resource consumption, security violations
Governance requirements (highest burden):
- Strict code review: All agent-generated tools reviewed by humans before use in production
- Staged permissions: Sandbox (unrestricted experimentation) → Review (human approval) → Staging (limited production test) → Production (full deployment)
- Security scanning: Automated analysis for injection vulnerabilities, credential leakage, resource abuse
- Comprehensive test coverage: Generated code must pass unit tests, integration tests, security tests before promotion
- Provenance tracking: Which agent version created which tool? When? For what use-case?
- Behavioral monitoring: Alert on unusual patterns (sudden skill creation spike, privilege escalation attempts, unexpected external connections)
When to consider: Only when you have a mature AI practice (operational for 2+ years), dedicated AI governance team with security expertise, proven track record at Level 5-6 with clean incident history, and explicit executive approval for self-modifying systems.
Typical use-cases: Research environments with rapidly evolving problem spaces, advanced automation R&D, systems that must adapt to frequent API/schema changes, exploratory data analysis with unknown data sources.
Research examples: Toolformer (LLM teaches itself when to call external tools), Voyager (Minecraft agent that writes reusable skill code), SWE-agent (software engineering agents that navigate repos and write code).
Where Should You Start? The Readiness Diagnostic
2-Minute Self-Assessment
Your starting level isn’t determined by ambition or budget—it’s determined by governance and organizational maturity. Score yourself honestly:
Governance Maturity (Score 0-2 for each):
- Versioning: Do you have version control for prompts/configs/tools with mandatory code review?
- Testing: Do you auto-run regression tests (20-200 scenarios) on every prompt/model change?
- Observability: Do you capture per-run telemetry (inputs, context, versions, tool calls, cost, output, human edits)?
- Incident response: Do you have playbooks with severities and a kill switch?
- Data protection: Are PII policies, retention rules, and data minimization implemented before pilots?
- Guardrails: Do you have policy checks, redaction, and prompt-injection defenses?
Organizational Readiness (Score 0-2 for each):
- Sponsorship: Do you have an executive sponsor with budget and an explicit, measurable ROI target?
- Ownership: Are there named roles—product owner + domain SME + SRE/on-call?
- Baseline: Have you documented current workflow timing, volumes, and human error rates?
- Definition of done: Have you agreed in writing what “correct,” “good enough,” and “unsafe” mean?
- Change management: Do you have a plan covering roles, training, KPI updates, compensation adjustments?
- Ops budget: Do you have ongoing budget (models, evals, logging, support) beyond the pilot?
Scoring → Recommended Starting Level:
| Total Score | Starting Level | Autonomy Ceiling |
|---|---|---|
| 0-6 | IDP (Level 2) | Advice-only pilots. No production actions without human approval. |
| 7-12 | RAG or Tool-Calling (Levels 3-4) | Human-confirm steps. Read-only or reversible operations only. |
| 13-18 | Agentic Loops (Levels 5-6) | Limited automation with rollback. Narrow scope, reversible-first. |
| 19-24 | Consider Self-Extending (Level 7) | You’re unusually mature—revisit risk appetite before proceeding. |
The Platform Economics: Why the First Use-Case Costs More
Here’s the financial argument that unlocks multi-year AI investment:
The first AI use-case costs $200K (60-80% is platform build). The second costs $80K because you reuse the observability stack, eval harness, vector database, deployment pipeline, and governance tooling.
Research validates the pattern: organizations that build reusable infrastructure see 2-3x faster deployment for subsequent use-cases.
What You’re Actually Building at Each Phase:
Phase 1: Foundational Platform (Levels 1-2)
- Document/data ingestion pipeline (ETL, connectors to source systems)
- Model integration layer (API calls to LLM providers with retry/fallback logic)
- Human review interface with approval workflows
- Metrics dashboard (accuracy, throughput, human review rate, cost per transaction)
- Cost tracking and budget alerting
Investment: ~60-70% of first use-case budget | Reuse: 80%+ for second use-case at same level
Phase 2: Evaluation & Observability Infrastructure (Levels 3-4)
- Eval harness with golden datasets and automated scoring
- Regression testing automation (CI/CD for AI—prompt changes trigger full eval suite)
- Vector database and retrieval pipeline (embeddings, similarity search, reranking)
- Tracing infrastructure (OpenTelemetry-based observability for LLM calls, tool invocations, retrieval steps)
- Prompt version control, A/B testing, and canary deployment system
Investment: ~50-60% of first RAG use-case budget | Reuse: 70%+ for second RAG use-case
Phase 3: Agentic Infrastructure (Levels 5-6)
- Multi-step workflow orchestration (state machines, DAG runners, retry logic)
- Guardrails framework (input validation, output filtering, policy enforcement, PII detection)
- Per-run telemetry and case lookup UI (debug any run in <2 minutes)
- Incident response automation (severity classification, auto-escalation, postmortem triggers)
- Budget caps, rate limiting, iteration limits (prevent runaway agents)
- Rollback and compensation mechanisms (undo multi-step operations)
Investment: ~40-50% of first agent use-case budget | Reuse: 60%+ for second agent use-case
How to sell this to leadership: Frame it as platform amortization. The second and third use-cases cost half as much and launch twice as fast because the scaffolding already exists. Calculate marginal cost per use-case and show the declining curve.
Cost reality leaders can accept: Initial deployment typically splits as:
- 15-25% model/prompt/task design
- 25-35% data integration & tool connectors
- 15-25% observability, environments, CI/CD, feature flags
- 10-15% security/compliance work
- 15-25% change management (training, comms, new KPIs, comp adjustments)
Pitch it as: “The model/prompt is the shiny 20%. The platform that keeps it working in production is the valuable 80%.”
Why This Pattern Works: Validation from Industry Leaders
1. All Major Maturity Frameworks Converge on Incremental Progression
Gartner, MITRE, MIT CISR, Deloitte, Microsoft—all publish maturity models with the same 5-level arc:
Awareness → Active (pilots) → Operational (production) → Systemic (embedded) → Transformational (DNA)
This organizational maturity progression mirrors the technical spectrum: IDP → RAG → Tool-Calling → Agentic.
Key Gartner finding: 45% of organizations with high AI maturity keep AI projects operational for at least 3 years. Low-maturity orgs abandon projects in <12 months. Maturity predicts longevity.
2. Cloud Providers Publish Reference Architectures for Each Level (Not “Skip to Agents”)
AWS:
- Guidance for Intelligent Document Processing (with human-in-the-loop review via Amazon A2I)
- Prescriptive Guidance for RAG (with evaluation frameworks, citation requirements, guardrails)
- Agentic AI Patterns & Workflows (multi-agent orchestration, Amazon Bedrock AgentCore)
Google Cloud:
- Document AI architecture (with Document AI Workbench, human review best practices)
- RAG Infrastructure using Vertex AI and AlloyDB (three control levels: fully managed → partly managed → full control)
- Agent Builder with ADK and hierarchical/sequential/MCP patterns
Azure:
- AI Document Intelligence reference architectures (automated classification, multi-modal content processing)
- RAG evaluation and deployment guidance
- AI Agent orchestration patterns (supervisor, custom, adaptive networks)
Takeaway: The incremental path (IDP → RAG → Agents) is the industry-standard pattern validated by all three major cloud providers. They don’t publish “jump straight to autonomous agents” guides because that path has a >80% failure rate.
3. Regulatory and Standards Bodies Mandate Governance Before Autonomy
EU AI Act (August 2025 enforcement, no grace periods):
- High-risk AI systems (which includes many agentic use-cases) must maintain detailed technical documentation, explainability records, and audit trails
- Fines up to €35M or 7% of global annual turnover for violations
- AI literacy requirements for all employees involved in deployment
- Copyright disclosure for training data
ISO/IEC 42001 (world’s first AI management system standard):
- 38 distinct controls covering governance, policy, risk management, impact assessment, lifecycle management, third-party oversight
- Designed to integrate with ISO 27001 (information security management)
- Addresses ethical considerations, transparency, continuous learning, bias mitigation, accountability, data protection
NIST AI Risk Management Framework:
- Four functions: GOVERN, MAP, MEASURE, MANAGE
- Voluntary but widely adopted as best practice baseline
- IEEE-USA built flexible maturity model on top of NIST AI RMF
- Gap: private sector implementation lags emerging consensus
Implication: Organizations deploying Level 6-7 autonomous agents without documentation, explainability, and governance will face regulatory compliance issues in 2025-2027.
4. Change Management Predicts Success More Than Technology
BCG 2024 research: Organizations that invest in change management are 1.6x as likely to report AI initiatives exceed expectations.
Yet:
- 87% of organizations faced more people/culture challenges than tech/organizational hurdles
- 38% cited insufficient training in AI tools as a primary barrier
- 51% of managers/employees say leaders don’t outline clear success metrics when managing change
- 50% of leaders don’t know whether recent organizational changes succeeded
The 70-20-10 rule validated: Successful AI governance allocates 70% of effort to change management and organizational readiness, 20% to data infrastructure, and only 10% to algorithms. Most organizations invert this ratio and fail.
If you skip change management—role impact analysis, training timelines, KPI/compensation updates for throughput changes—you create resistance and sabotage. Users will find ways to make the AI “look bad” if they perceive it as a threat.
Defusing the “One Bad Anecdote Kills the Project” Pattern
Set error budgets and severity classes up front, published side-by-side with human baseline performance:
| Severity | Definition | Response | Example Tolerance |
|---|---|---|---|
| SEV3 (Low) | Harmless inaccuracies (spelling, tone, formatting) | Log and continue | Allowed within 5-10% |
| SEV2 (Medium) | Correctable workflow errors (needs human check) | Auto-escalate to human review | Must escalate, but expected 1-5% |
| SEV1 (Critical) | Policy/PII violations, financial harm, compliance breach | Immediate rollback, incident review | Zero tolerance |
Publish a weekly quality dashboard to keep anecdotes from beating data. When someone says “the AI made a mistake,” you respond with evidence:
“Yes, we had 1 SEV2 escalation out of 847 runs this week. Our error budget is 5 SEV2 per week (based on human baseline of 0.6% error rate). We’re within tolerance, the case auto-escalated to human review within 30 seconds, and here’s the postmortem on what triggered it.”
Make quality visible and evidence-based, not political. Define “correct” and “good enough” in writing before you deploy. Otherwise, you’re vulnerable to shifting goalposts.
Implementation Roadmap: Your First 90 Days
Phase-Gated Deployment Timeline
Day 1-30: Pilot at Your Starting Level
- Take the readiness diagnostic (score governance + organizational maturity)
- Pick your starting level based on score (0-6 → IDP; 7-12 → RAG; 13-18 → Agentic)
- Build minimal platform for that level (ingest pipeline, model integration, basic metrics)
- Ship a narrow use-case in shadow mode (AI proposes, humans act)
- Capture baseline metrics: human timing/error rate vs. AI timing/error rate
Day 30-60: Build Observability and Governance
- Add eval harness with 20-50 test scenarios from real production cases
- Implement version control for prompts/configs with mandatory code review
- Set up per-run telemetry (inputs, context, versions, tool calls, cost, output)
- Define error budgets and severity classes with incident playbooks
- Move from shadow mode to assist mode (AI acts, sampled QA by humans)
Day 60-90: Scale Within Level, Prepare for Next
- Expand to full production at current level (narrow auto for reversible actions)
- Ship second use-case reusing platform (measure 2-3x faster deployment)
- Run change management program (training, KPI updates, weekly quality dashboard)
- Assess readiness to advance: error rate in budget? Governance mature? Team confident debugging?
- If yes: plan next-level platform additions (RAG → vector DB; Agentic → guardrails + orchestration)
Day 90+: Advance to Next Level or Deepen Current Level
Only advance when:
- Quality metrics stable (no regression in eval suite for 4+ weeks)
- Incident rate within budget (SEV1 = 0, SEV2 < defined threshold)
- Change failure rate <15% (prompt/model changes that cause issues)
- Team can debug failures using telemetry in <2 minutes
- Organizational support strong (executive sponsor still engaged, users trained, no political backlash)
Common Pitfalls and How to Avoid Them
Pitfall 1: Skipping Levels to “Catch Up” to Competitors
Symptom: “Our competitor deployed agents, so we need to deploy agents.”
Fix: Competitors who skip levels have a 70-95% failure rate. You’re watching their press releases, not their postmortems. Start at the right level for your maturity, not theirs.
Pitfall 2: Building One-Off Solutions Without Platform Thinking
Symptom: Each use-case is a separate project with separate observability, separate deployment, separate tooling.
Fix: Your second use-case should cost 50-60% less and ship 2-3x faster. If it doesn’t, you haven’t built a platform—you’ve built a pile of pilots. Invest in reusable infrastructure up front.
Pitfall 3: Treating Governance as “Nice to Have” Post-Launch
Symptom: “Let’s ship fast and add observability later.” Or: “We’ll formalize the eval suite after we prove value.”
Fix: Governance debt compounds faster than technical debt. Without observability, you can’t debug failures. Without eval harnesses, you can’t change prompts safely. Build governance scaffolding before you ship.
Pitfall 4: Ignoring Change Management Until Deployment
Symptom: Users resist the AI, find edge cases to make it look bad, or refuse to adopt it.
Fix: Start change management T-60 days before launch. Role impact analysis, training-by-doing in shadow mode, KPI/comp updates if throughput expectations change. BCG: orgs that invest in change mgmt are 1.6x likelier to exceed expectations.
Pitfall 5: No Defined “Definition of Done” or Success Criteria
Symptom: Stakeholders argue about whether the AI is “good enough” or “accurate enough” based on anecdotes.
Fix: Before you deploy, agree in writing: What is “correct”? What is “good enough”? What is “unsafe”? What’s the human baseline error rate? What error budget makes sense? Publish weekly dashboards to make quality visible.
Conclusion: Start Simple, Scale Smart
The data is unambiguous:
- 70-95% of enterprise AI projects fail
- 70% of failures are organizational (governance, change management, clarity), not technical
- All major maturity frameworks converge on incremental progression
- All major cloud providers publish incremental reference architectures (IDP → RAG → Agents)
- Organizations with high AI maturity keep projects operational 3+ years; low-maturity orgs abandon in <12 months
- Platform reuse enables 2-3x faster deployment for subsequent use-cases
The path to durable AI ROI isn’t a leap to autonomous agents. It’s a systematic climb:
- Assess your maturity (governance + organizational readiness)
- Start at the right level for your score (don’t skip rungs)
- Build the platform incrementally (observability, evals, governance)
- Ship use-cases that prove value and build organizational trust
- Advance when ready—when error rates are in budget, governance is mature, and the team can debug failures
Organizations that follow this pattern don’t just deploy AI—they build durable AI capability that compounds over time. The second use-case costs half as much. The third ships in a quarter of the time. Governance becomes muscle memory. Users trust the systems because they’ve seen incremental, evidence-based quality improvements.
Those that leap to Level 7 autonomous agents with Level 2 governance hit the “one bad anecdote kills the project” trap. Six months of work canceled over a single visible mistake.
Start simple. Scale smart. Climb the spectrum systematically.
Discover more from Leverage AI for your business
Subscribe to get the latest posts sent to your email.
You may also like...
- Blog Posts
- The Fast-Slow Split: Breaking the Real-Time AI Constraint
- SiloOS: The Agent Operating System for AI You Can’t Trust
- The AI Executive Brief: November 2025
- The AI Think Tank Revolution: Why 95% of AI Pilots Fail (And How to Fix It)