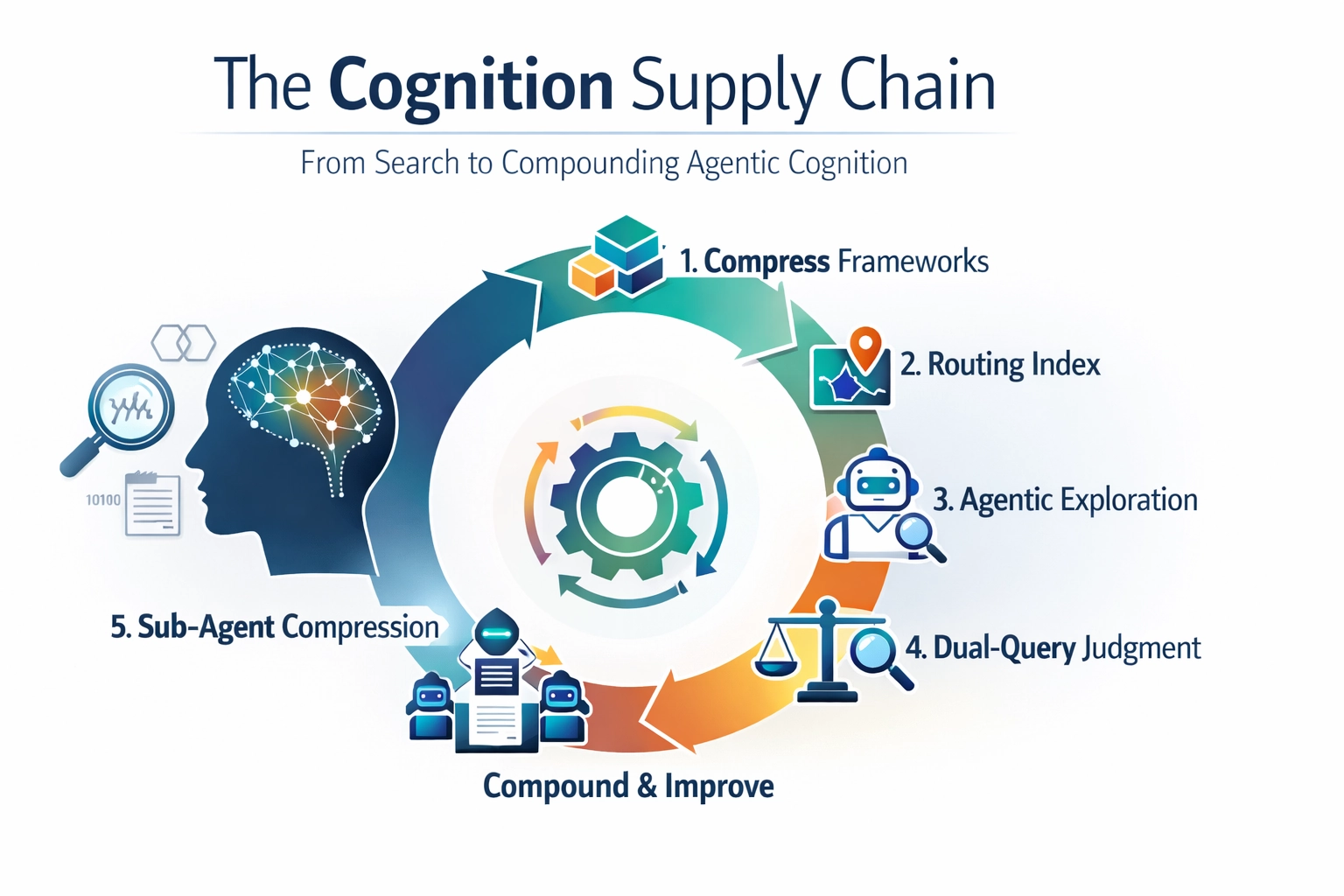
The Cognition Supply Chain
From Search to Compounding Agentic Cognition
📘 Want the complete guide?
Learn more: Read the full eBook here →
TL;DR
- Your AI outputs are generic because there’s no supply chain feeding the right context at the right time — not because your model is dumb.
- Five stages fix this: compressed frameworks → routing index → agentic exploration → dual-query judgment → sub-agent compression.
- Each cycle compounds: better frameworks → better search priors → better exploration → better compression → better frameworks. Architecture compounds. Model upgrades don’t.
The Problem Nobody Talks About
You upgraded to the frontier model. Your outputs are still generic.
Not wrong, exactly. Just… flat. The kind of output that could have been written about any company, any industry, any problem. You spent the money on the latest model, fed it your documents, maybe set up RAG — and you got back fluent mediocrity.
Here’s the uncomfortable truth: the model isn’t the bottleneck. The supply chain feeding it is.
Think about it this way. If you ask AI about blue whales — population trends, migration patterns, conservation status — you’ll get a brilliant answer from almost any model. That’s a stable domain: decades of research, slow-moving consensus, bounded disagreement. The model’s training data handles it perfectly.
Now ask AI how to implement AI in your specific organisation. You’ll get a fog of plausible-sounding generalities. Not because the model is dumb, but because the prompt is effectively: “Please search an unbounded space of possibilities and also guess which constraints I forgot to mention.”
Blue whales are easy. Your business is hard. The difference isn’t model intelligence. It’s context architecture.
Anthropic’s own engineering research confirms this: context must be treated as a finite resource with diminishing marginal returns — LLMs have an “attention budget” that degrades when parsing large volumes of irrelevant context.1 Double your context size and you’ve quadrupled the computational load.2 More isn’t better. Sharper is better.
What you need isn’t a smarter model. You need a cognition supply chain — an architecture that routes the right knowledge, explores it deeply, judges what matters, compresses it to pure signal, and compounds with every cycle.
Stage 1: Compress Your Knowledge Into Frameworks
Before anything enters the pipeline, you need raw material worth processing. And the best raw material isn’t documents, wikis, or meeting transcripts — it’s compressed domain frameworks.
I run conversations where models with 18-month-old training data produce expert-level output. Not because the model is special, but because my frameworks collapse the search space brutally. Instead of navigating an infinite space of possibilities, the model navigates a map I already drew.
Frameworks act as a compression codec for organisational reality. They turn messy, high-entropy problems — like “how should we implement AI?” — into a small set of named shapes the system can reliably reason with. Once you name the shapes (your decision rules, your deployment philosophy, your governance model), the model stops inventing wisdom and starts navigating a map.
This is Worldview Recursive Compression in practice: compile your domain expertise into frameworks that serve as the “kernel” loaded into every AI interaction. Each framework is source code. Every output is a regenerable binary. Fix the source once, and all future outputs improve.
But frameworks alone aren’t enough. You need a way to navigate them.
Stage 2: Give the Agent a Map
When an agent starts cold against a corpus, it has two problems:
- Vocabulary problem: It doesn’t know what terms exist in your world, so it can’t form good retrieval queries.
- Topology problem: It doesn’t know what’s important, central, foundational, or dependent.
Without solving both, the agent performs an expensive random walk through your knowledge. It uses the only words it has — the words from the current problem — and hopes they happen to match something useful. Sometimes they do. Often they don’t. This is the prompt lottery, and most organisations are playing it daily.
The fix is a routing index — a machine-readable map of your knowledge corpus that provides what Information Foraging Theory calls “information scent.”3
Information scent works like labels on trails in a national park. Good labels (“Waterfall 2km, Lookout 500m”) let you estimate value before paying the cost of walking. Bad labels (“Nature Walk”) tell you nothing. No labels at all means you wander.
A routing index provides:
- Framework names and one-liners (what concepts exist here)
- “Retrieve when” triggers (when each framework becomes relevant)
- Tags and related concepts (how frameworks connect to each other)
- URLs or pointers (where to dig deeper)
This isn’t documentation. It’s a control surface. It enables guided exploration, backtracking by design, and hierarchical retrieval. The academic research calls this approach “RAPTOR” — hierarchical retrieval with tree-structured summaries across levels of abstraction.4 A routing index is the lightweight, human-curated version of that idea.
I’ve been underestimating how powerful this is. My routing index lists the major documents, frameworks, when to use them, and the URLs to find more. Instead of starting the search empty, you’re giving the LLM a geography map. The first search is immediately on target because the agent can see which concepts exist in the corpus and which ones are likely relevant to the current problem.
Stage 3: Explore, Don’t Just Retrieve
Standard RAG is: query → vector similarity → top-k chunks → generate. It works for simple, local questions (“find the paragraph about X”). It fails badly for dependency-shaped questions (“X is defined in doc A but constrained by doc B and exceptioned by doc C”).
And most real enterprise knowledge is dependency-shaped. Policies reference other policies. Contracts constrain workflows. Specs depend on other specs. Chunking loses this global context entirely. Semantic similarity looks at a few chunks most similar to your query and completely ignores cross-references.5
The alternative is agentic exploration — treating retrieval as an investigation, not a lookup.
The Retrieval Maturity Ladder
| Level | Pattern | What It Does |
|---|---|---|
| 1 | System prompt stuffing | Pad 2,500 tokens of context. Static, brittle, goes stale. |
| 2 | Tool-calling RAG | LLM invokes retrieval tools. Single-shot: retrieve + generate. |
| 3 | Agentic RAG | Agent reformulates queries, spots gaps, asks for more. Iterative but still chunk-bound. |
| 4 | Agentic exploration + compression | Agent explores files directly, follows cross-references, backtracks. Parallel reviewer agents compress findings. |
Level 4 looks like how coding agents work: they skim, search, jump to definitions, follow imports and references, “open the next file because that file points to it.” This is exploration as retrieval — treating the file system plus basic text tools as the primary substrate for finding truth.
Agentic file exploration uses a three-phase process:
- Parallel scan: Preview all documents quickly to identify which contain relevant information.
- Deep dive: Fully parse and read only the promising documents. The LLM can identify cross-references that were missed in the initial scan.
- Backtrack: Follow those cross-references to documents you didn’t initially pick up.
The tradeoff is real: agentic exploration is slower and more expensive than RAG at scale, making it better for background or asynchronous tasks.6 RAG wins for real-time scenarios. The practical answer is hybrid: RAG as the broad net for fast candidate generation, exploration as the truth-finding scalpel for dependency-shaped questions. This maps directly to the Fast-Slow Split — exploration is the slow thinker doing heavy cognition off the clock.
The Dual-Query Pattern
Here’s a trick most retrieval systems miss: retrieval and reasoning want different inputs.
Your retrieval query should be broad and recall-heavy — don’t miss anything. Your goal specification should be rich and intention-heavy — what you actually need. Conflating them guarantees mediocre results.
Example: You’ve got a manufacturing client struggling to find where to start with AI. If you put “manufacturing AI implementation starting point” into your semantic search, you’ll get content about manufacturing processes, factory automation, supply chain optimisation. Completely off-target.
Instead, keep the retrieval query broad: “AI implementation failure modes, where to start, governance readiness.” Then send the full context — “manufacturing client, early-stage, needs safe starting lane” — to a judgment layer that evaluates retrieved results against the actual goal.
I built exactly this pattern for image search. Keyword search returns 10 thumbnails for “kookaburra.” An LLM judge separately evaluates those thumbnails against the real goal: “zoomed-in kookaburra in a gum tree.” The search engine can’t distinguish — but the LLM judge can. Same pattern generalises to text retrieval.
Modern search APIs already converge on this. Tavily’s two-step flow separates search (find candidates) from extract (pull relevant content).7 Claude’s web-search tool runs iterative loops: search, evaluate, search again.8 The industry is moving from “one-shot retrieve” to “agentic search with summarisation.”
Stage 4: Compress Through Sub-Agents
Exploration is expensive. A deep investigation might burn 200,000 tokens — reading documents, following cross-references, evaluating relevance, resolving contradictions. You can’t dump all that into your main agent’s context. It would drown in noise.
The solution is scatter-gather for cognition.
- Main agent = orchestrator. Holds the map, goals, constraints, and evaluation criteria.
- Sub-agents = explorers. Each starts with a clean slate, goes deep on one aspect, then returns a distilled memo.
Anthropic’s engineering research confirms this: “The essence of search is compression — distilling insights from a vast corpus. Subagents facilitate compression by operating in parallel with their own context windows, exploring different aspects of the question simultaneously.”9
Their internal evaluations show multi-agent research systems excel for breadth-first queries involving multiple independent directions.9 On complex engineering tasks, multi-agent orchestration achieves a 90.2% success rate compared to 14–23% for single-agent approaches.10
In my proposal workflows, a sub-agent might spend 200,000 tokens on research, briefing, and writing. But the outcome is 20,000 tokens of applicable, client-specific research. The 200,000 tokens vanish when the sub-agent terminates. The main agent only reads the compiled memo — pure signal, zero noise.
Context isolation is secretly great for quality control. Sub-agents can thrash around, contradict themselves, chase weird leads — and the main agent never sees the mess. Only the compiled memo survives.
The priming challenge is real: sub-agents start empty, so you need to brief them well. The fix is to treat priming like a function call, not a story:
- Mission: What decision or outcome are we trying to enable?
- Non-goals: What not to spend tokens on.
- Constraints: Governance, risk, tools allowed.
- Client context: The 10 facts that matter (not 100).
- Framework anchors: The relevant named frameworks plus one-liners.
- Deliverable format: Findings, implications, recommended moves, citations, open questions.
This is Context Engineering in practice — sub-agents as ephemeral sandboxes that isolate messy work, then emit clean artefacts that preserve the main agent’s working memory.
The token economics are compelling: burn cheap tokens on exploration in isolated contexts, preserve expensive main-context tokens for synthesis and judgment.
Stage 5: The Compounding Loop
Here’s where the cognition supply chain becomes something more than a pipeline. It becomes a flywheel.
When agents can retrieve, each read changes the next question. The query gets sharper, so the next retrieval is more relevant, so the next query gets sharper again. That’s information foraging with feedback — and it compounds.
But the real compounding happens across cycles:
- Better frameworks (Stage 1) produce better routing indexes (Stage 2).
- Better routing feeds sharper exploration queries (Stage 3).
- Sharper exploration produces higher-quality compressed artefacts (Stage 4).
- Higher-quality artefacts reveal gaps and patterns that improve the frameworks (back to Stage 1).
Each cycle makes the next one better. The frameworks you build today solve problems you haven’t encountered yet. This is what compounding agentic cognition actually looks like — not a bigger model, but a tighter loop.
It does hit diminishing returns eventually, unless you add two things:
- A scoring function: What counts as “progress”? Risk reduced, uncertainty collapsed, decision narrowed, value unlocked.
- A compression step after each cycle: Convert what you learned into a tighter map — a new rule, a new heuristic, a new “don’t do this” constraint. So the next run starts smarter.
This is what separates the cognition supply chain from a one-shot pipeline. It’s the Three Ingredients — Agency, Tools, and Orchestration — working together to create compounding returns. Remove any one, and the system collapses back to linear performance.
The Full Pipeline
| Stage | What Happens | Key Pattern |
|---|---|---|
| 1. Compress | Domain knowledge compiled into reusable frameworks | Named shapes the model can navigate |
| 2. Route | Routing index provides information scent | Geography map, not random walk |
| 3. Explore | Agentic exploration with dual-query judgment | Broad retrieval, sharp judgment |
| 4. Compress (again) | Sub-agents distill 200K tokens to 20K | Scatter-gather for cognition |
| 5. Compound | Artefacts improve frameworks for next cycle | Flywheel, not pipeline |
The practical starting point isn’t building all five stages at once. It’s this:
- This week: Write 10 framework one-liners with “retrieve when” triggers. That’s your routing index v0.1.
- This month: Wire one sub-agent to explore your knowledge base using the routing index, then compress findings to a memo.
- This quarter: Add the dual-query pattern — separate retrieval queries from goal specs. Add a second sub-agent for parallel exploration.
- Ongoing: After each project, update the routing index with new patterns and frameworks. The flywheel starts turning.
The beauty of this architecture is that you build it incrementally. Each stage is useful on its own. But together, they compound into something that makes the specific model you’re running almost beside the point.
The system gets smarter. The model doesn’t need to.
scott@leverageai.com.au • leverageai.com.au
References
- [1]Anthropic. “Effective Context Engineering for AI Agents.” — “Context must be treated as a finite resource with diminishing marginal returns. Like humans, who have limited working memory capacity, LLMs have an ‘attention budget’ that they draw on when parsing large volumes of context.” anthropic.com/engineering/effective-context-engineering-for-ai-agents
- [2]Zandieh et al. “On The Computational Complexity of Self-Attention.” — Self-attention scales quadratically (O(n²)) with sequence length; doubling context size quadruples computational load. arxiv.org/abs/2209.04881
- [3]Nielsen Norman Group. “Information Foraging: A Theory of How People Navigate the Web.” — Information scent: cues that help users estimate the value of a path before paying the cost of exploration. nngroup.com/articles/information-foraging/
- [4]Sarthi et al. “RAPTOR: Recursive Abstractive Processing for Tree-Organized Retrieval.” — Hierarchical retrieval with tree-structured summaries retrieving across levels of abstraction, addressing chunking’s global context loss. arxiv.org/abs/2401.18059
- [5]Microsoft. “RAG Chunking Phase — Parent-Child Retrieval.” — Parent-child retrieval uses small chunks for semantic matching (recall) and parent sections for context (precision), but still misses cross-document dependencies. learn.microsoft.com/en-us/azure/architecture/ai-ml/guide/rag/rag-chunking-phase
- [6]LlamaIndex. “Did Filesystem Tools Kill Vector Search?” — File-explorer agents match RAG quality but with higher latency, making them better for background/asynchronous tasks. llamaindex.ai/blog/did-filesystem-tools-kill-vector-search
- [7]Tavily. “Tavily 101: AI-Powered Search for Developers.” — Two-step flow: /search finds candidates with concise LLM-optimised snippets, /extract pulls full cleaned content. tavily.com/blog/tavily-101-ai-powered-search-for-developers
- [8]Anthropic. “Claude Web Search Tool.” — Claude’s web-search tool runs iterative loops: Claude decides when to search, the API runs searches, and this can repeat multiple times in one request. platform.claude.com/docs/en/agents-and-tools/tool-use/web-search-tool
- [9]Anthropic. “Building Effective Multi-Agent Research Systems.” — “The essence of search is compression: distilling insights from a vast corpus. Subagents facilitate compression by operating in parallel with their own context windows.” anthropic.com/engineering/multi-agent-research-system
- [10]Anthropic. “Building Effective Agents.” — Multi-agent orchestration achieves 90.2% success rate vs 14–23% for single-agent approaches on SWE-bench. anthropic.com/research/building-effective-agents
Discover more from Leverage AI for your business
Subscribe to get the latest posts sent to your email.