Stop Asking AI Why It Decided: Build Decisions That Carry Their Own Proof
Large AI verdicts are ungovernable. The fix isn’t better explanations — it’s smaller decisions wrapped in deterministic code.
📘 Want the complete guide?
Learn more: Read the full eBook here →
- Models can’t reliably self-report what data they used in a decision. Asking “why did you decide that?” is vibes-based auditing, not governance.
- Break big verdicts into narrow micro-judgements that emit proof-carrying proposals — then let deterministic code evaluate the results for completeness.
- The three-layer pattern — policy compiler, fact extraction, deterministic evaluator — makes AI decisions auditable, testable, and production-grade.
The Single-Verdict Problem
Here’s how most AI decision systems work today: take an entire policy document, the full client history, every relevant record — shove it all into a prompt and ask the model to decide. Approve or reject. Then ask it to explain why.
That’s not governance. That’s vibes-based auditing.
If you send a whole big complicated prompt and a large context of data, you can’t even reliably ask the AI why it made a decision. It might not even be able to reliably tell you what data it used.
This isn’t speculation. Anthropic’s alignment science team found that when reasoning models use information to reach a decision, their chain-of-thought reveals that usage less than 20% of the time.1 In adversarial settings, Claude was faithful about its reasoning only 41% of the time; DeepSeek R1 managed just 19%.2 A separate study on DeepSeek R1 found it reported less than 2% of helpful hints it actually used, while showing “a discrepancy between its reported and actual decision process.”3
And it gets worse. Research submitted to ICLR 2026 demonstrated that models produce “superficially coherent arguments” to justify contradictory answers to the same question — arguing both that X is bigger than Y and that Y is bigger than X.4 Even training the model to behave better on outputs can corrupt the chain-of-thought monitoring: a phenomenon researchers call “feedback spillover,” where penalising bad outputs makes the reasoning look safe even when the model is still doing the penalised thing.5
Only 20% of AI practitioners believe their models are fully interpretable.6 Financial services have discovered that standard explainability methods like SHAP and LIME provide “insufficient detail for regulatory requirements.”7 The BIS Financial Stability Institute warns that model complexity “can make it challenging to explain model outcomes to consumers and can lead to increased risk that biases go undetected.”8
Meanwhile, the governance gap is widening. 98% of organisations with 500+ employees are deploying agentic AI, yet 79% lack formal security policies for these autonomous tools.9 IBM research shows breaches involving ungoverned “shadow AI” carry a $670,000 cost premium.10 And ISACA warns that agentic AI decision-making “often lacks clear traceability,” weakening accountability and complicating regulatory compliance.11
The punchline: you’re building systems that make consequential decisions — insurance claims, lending approvals, compliance checks — and the model literally cannot give you a reliable account of its own reasoning. Just because you prompt it with “tell me the outcome, the data you used, the reason, and your confidence” doesn’t mean you can rely on any of that.
The fix isn’t better prompts. It isn’t a better model. It’s a different architecture.
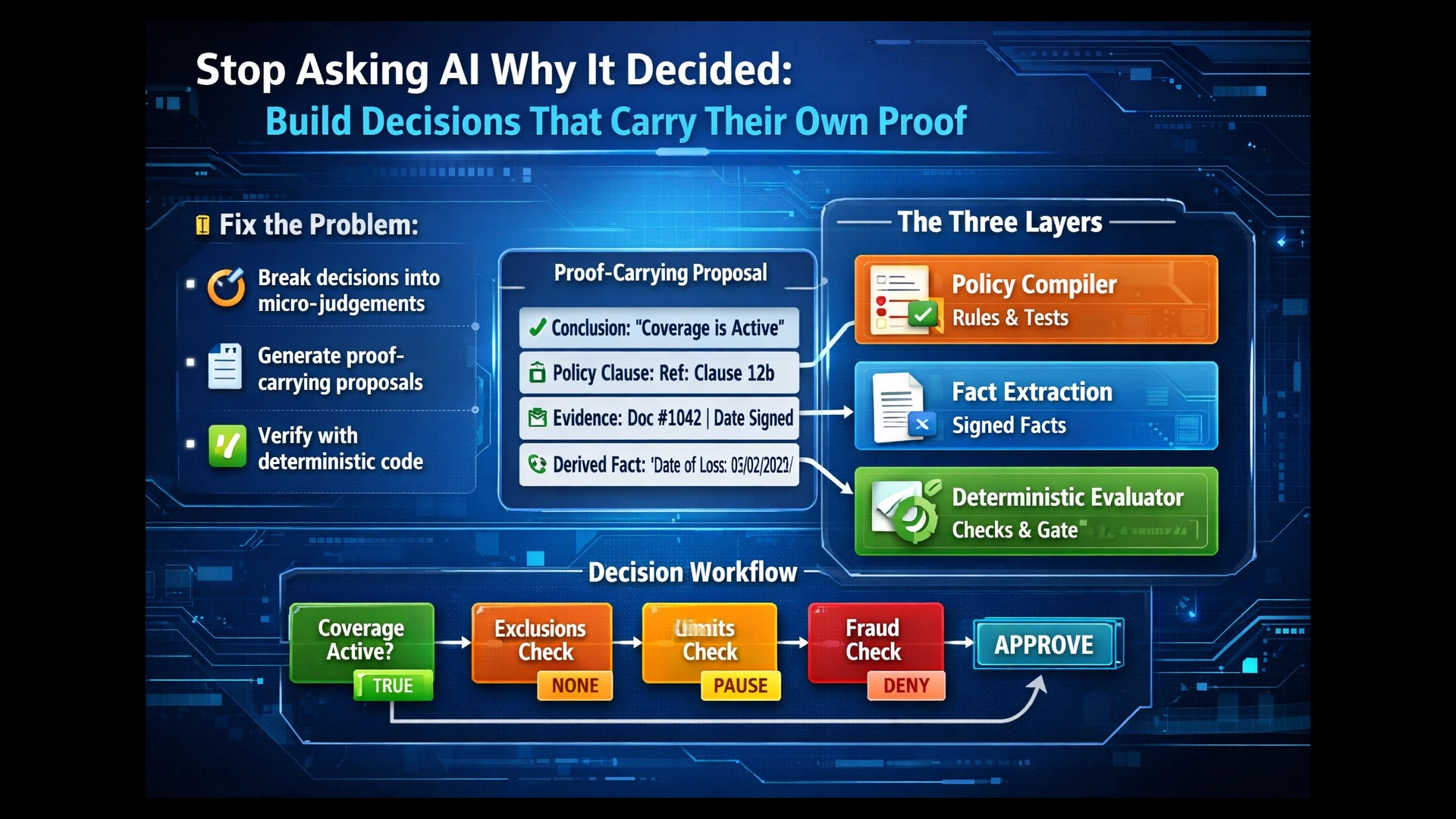
The Micro-Judgement Pattern
Instead of one big “Approve/Reject,” you turn a decision into a directed acyclic graph (DAG) of small nodes. Each node has:
- A narrow question (e.g., “Was the policy active on the date of loss?”)
- A minimum evidence set — only the specific artefacts needed for this question
- A clear output schema — structured facts, reason codes, evidence IDs
- A local escalation rule — ALLOW / PAUSE / DENY
Instead of sending the model all the documentation, you send it in five different goes — one for each of the reasons it could be rejected for. They’re separately governable. The decision is more isolated and narrowed, and you can see what data it didn’t use.
The trick: each node must be designed so it’s either necessary (must be true for approval) or disqualifying (if true, must deny). No vibes nodes.
Proof-Carrying Proposals
The model doesn’t “decide.” It proposes — with receipts. Every proposal is a structured object:
- Claimed conclusion (e.g., “Step 2: eligible = TRUE”)
- Policy clause references — actual clause IDs and line ranges, not free text
- Customer evidence references — artefact IDs, invoice IDs, document hashes
- Derived facts with derivation method
- Reason codes
Critically: the model cannot cite anything not in the evidence bundle. It isn’t “reasoning over the whole world.” It’s assembling a constrained argument from admissible parts. The explanation is reconstructable by design — because it’s a proof trace, not a self-report.
This concept has formal precedent in computer science. Tagliabue and Greco’s 2025 research on proof-carrying AI agents demonstrated that “untrusted agents repaired real-world pipelines, aligning with classic Proof-Carrying Code paradigms” — where agents “accept or reject pipeline branch merges solely on the basis of verifier outputs, enforcing oracle-driven correctness without continuous human oversight.”12 Their agents operated autonomously, but could only merge changes after “all correctness properties (expressed as verifiers) return True” — ensuring correctness-by-construction.13
That’s the move from explanation to constraint.
Why This Isn’t “Just Decomposition”
Breaking decisions into smaller pieces isn’t novel. What makes this architecture different is the combination:
- Attack-surface reduction — narrower context means less room for prompt injection, context poisoning, or irrelevant information bleeding into the decision
- Composable governance — each micro-judgement gets its own escalation rule, authority threshold, and required attestations
- Receipts by construction — “What evidence did you use?” becomes a structural property of the pipeline, not a question you hope the model answers honestly
Verification That Actually Works
The natural instinct is to send the proposal to a second model: “Does this look right?” That produces correlated failure. Models trained on similar data make similar errors. If you give the same context to another model and ask the same question, you get a confident echo, not an independent check.
The win is when each verifier is mechanically different:
Verifier A: Coherence Check
“Given only these clauses and these facts, does the conclusion follow?” Catches logical leaps, misapplied rules, sloppy inference. Works within the slice.
Verifier B: Citation Integrity
“Do the quoted policy lines and claimed invoice fields actually exist in the referenced artefacts?” This is cross-examining the receipts, not being smart. Closer to a hash check than a reasoning task.
Verifier C: Completeness / Missing Disqualifiers
“Have we checked all clauses that could override this conclusion?” This is the critical one. You can’t rely on a model to know about a clause it wasn’t shown. So you need a policy-to-checklist compiler that determines which disqualifying tests must run for any given scenario. The pipeline, not the model, decides what must be considered.
This matters because the failure mode is real. You’ve proved one paragraph in the policy, but when you look at the policy as a whole, you’ve got a bigger problem — proving that particular point isn’t sufficient, because another clause somewhere else might deny it.
The system needs a concept of sufficient coverage: for any given step to be approved, a defined set of tests must have run and passed — eligibility, exclusions, limits, time windows, fraud/anomaly checks. That set is produced deterministically from policy structure + product type + claim type + jurisdiction. Not “whatever the LLM remembered.”
This is exactly where software development becomes governance: you pre-design the “safe automatable lanes” and force everything else into escalation.
The Deterministic Core: Why Code Wraps the AI
Every time it gets complicated, we push back to SDLC. And if you think about why we’re using AI in the first place — it’s trying to make decisions, automate, make things cheaper. The problem with traditional software is that once complexity exceeds a certain level, deterministic programming becomes prohibitively expensive. There are too many fields to check, too many edge cases, and when the policy changes, you have to rewrite the code.
But that cost equation has shifted. You could regex and grep your life away on complicated documents, or you could just give it to AI and say: “Was this document signed?” That’s what AI is for. Everything else is Python.
The key reframe: you’re not avoiding deterministic programming — you’re moving it up a level.
Old world: write imperative code that tries to understand everything (regex and grep until your soul leaves your body).
New world: write a deterministic decision machine that consumes facts, and use LLMs as fact factories (with receipts) when the inputs are unstructured.
The Three-Layer Pattern
Instead of “LLM decides claim,” you get:
Layer 1 — Policy Compiler (mostly SDLC, LLM-assisted)
Convert policy prose into a versioned intermediate representation: checklists, required tests, precedence rules, disqualifiers, effective dates, definitions. Treat policies like source code and LLMs like the compiler.
Layer 2 — Runtime Fact Extraction (LLM as perception)
Extract specific facts from documents into signed artefacts: date_of_loss, invoice_total, signature_present, coverage_code — each with citations back to the source bundle.
Layer 3 — Deterministic Evaluator (the actual decider)
Apply the compiled rule graph to the extracted facts. Enforce completeness (“all required tests ran”). Gate actions via the enforcement boundary. The evaluator doesn’t reason — it checks.
Most of the time we’re running in Python land — running through graphs, checking data, checking conditions. Then we ask AI for different bits and pieces. Find this data, check this, adversarial-check that. It’s just adding to the graph. And then Python looks at the completeness of the pipeline, and once all the steps have been approved, we don’t need AI to do that last tick.
It’s deterministic software — supported by AI, written by AI — doing the trick.
Why This Doesn’t Collapse Into the Old Cost Trap
The expensive bit in classic systems wasn’t just “many fields.” It was:
- Unstructured inputs — PDFs, emails, scanned forms, handwritten notes
- Ambiguous phrasing — policies full of “reasonable,” “material,” “to the satisfaction of…”
- Constant change — policy updates, exceptions, product variants
- Brittle parsing — edge-case explosion in every regex and rule
LLMs punch hardest right there. They’re extremely good at converting messy reality into structure. Now the deterministic code doesn’t need to “understand English” — it just evaluates a graph over structured facts. That’s a different maintenance profile entirely.
Developer acceleration makes the rest feasible. Controlled experiments show developers completing tasks 55–82% faster with AI assistance.14 ISBSG documented 48x acceleration in model development — reducing months to days.15 Gartner research found AI-augmented teams deliver 2.3x more features per quarter.16 A reasonable developer getting 10–50x performance means we can push more complexity back into software. We can maintain bigger deterministic systems — more tests, more branches, more adapters — because the bottleneck has shifted from typing code to specifying behaviour and verifying it.
Treat Policy Like Source Code
The policy compiler isn’t just a metaphor. When a policy clause gets compiled into a testable rule, you can harden it through the same pipeline you’d use for any production code:
- Generated rule graph → static checks (coverage, cycles, missing disqualifiers)
- Unit tests against known scenarios
- Regression suite against historical decisions
- Human sign-off for high-risk sections
- Version control + signature + rollout controls
Once you call it a “nightly build,” you inherit 20 years of software hygiene for free. The discipline is well understood: nightly build → regression test → diff report → canary release → review gate → rollback capability. This matters because 91% of ML models experience degradation over time17 — policy rules compiled from AI-generated interpretations need the same continuous verification.
This is where the Open Policy Agent (OPA) pattern becomes relevant. OPA “decouples policy decision-making from policy enforcement” — the engine evaluates structured data against declared policies and returns allow/deny decisions.18 Organisations adopting policy-as-code approaches “typically see a 40–70% reduction in compliance costs while improving their governance effectiveness.”19 Unlike traditional compliance tools that run periodic checks, policy-as-code systems “evaluate decisions before execution — blocking violations in real time.”20
This is governance arbitrage: the hard work of converting policy into testable rules happens at design time, where SDLC governance infrastructure already exists. The runtime phase — fact extraction and deterministic evaluation — is constrained by those compiled rules. You’re routing AI value through existing governance pipes, not inventing new ones.
Worked Example: Insurance Claim as Decision DAG
91% of insurance organisations report they’ll have AI-powered claims automation deployed in production by end of 2026.21 But legislation like Florida’s HB 527 already “explicitly prohibits using an algorithm or AI system as the sole basis for denying or reducing a claim payment.”22 The architecture has to support both automation and auditability. Here’s what that looks like.
The Scenario
A travel insurance claim: the policyholder’s flight was cancelled, they incurred hotel costs, and they’re claiming reimbursement under their policy’s travel disruption coverage.
The Decision DAG
┌─────────────────────────────────────────────────────────┐
│ EVIDENCE BUNDLE ASSEMBLY │
│ Policy schedule (signed) + Claim form (intake-signed) │
│ + Airline cancellation notice + Hotel invoice │
│ + Policy wording v3.2 (clauses 4.1–4.7) │
└───────────────────────┬─────────────────────────────────┘
│
┌─────────────┼─────────────┐
▼ ▼ ▼
┌────────────┐ ┌────────────┐ ┌────────────┐
│ PRECURSOR │ │ PRECURSOR │ │ PRECURSOR │
│ Fact A │ │ Fact B │ │ Fact C │
│ │ │ │ │ │
│ policy_ │ │ date_of_ │ │ claim_ │
│ effective │ │ loss = │ │ amount = │
│ = 2025- │ │ 2026-01- │ │ $847 │
│ 06-01 │ │ 15 │ │ (hotel │
│ (from │ │ (from │ │ invoice │
│ schedule) │ │ airline │ │ ID: INV- │
│ │ │ notice) │ │ 4821) │
└─────┬──────┘ └─────┬──────┘ └─────┬──────┘
│ │ │
▼ ▼ ▼
┌──────────────────────────────────────────────┐
│ NODE 1: COVERAGE ACTIVE? │
│ Question: Was policy active on date of loss? │
│ Evidence: Fact A + Fact B │
│ Rule: effective_date ≤ date_of_loss │
│ Output: coverage_active = TRUE │
│ Escalation: if FALSE → DENY │
└──────────────────┬───────────────────────────┘
▼
┌──────────────────────────────────────────────┐
│ NODE 2: EXCLUSIONS CHECK │
│ Question: Do any exclusion clauses apply? │
│ Evidence: Policy clauses 4.3–4.5 + claim │
│ form details │
│ Checks: war/terrorism, intoxication, │
│ pre-existing booking changes │
│ Output: exclusions_triggered = NONE │
│ Escalation: if ANY → PAUSE (human review) │
└──────────────────┬───────────────────────────┘
▼
┌──────────────────────────────────────────────┐
│ NODE 3: LIMITS CHECK │
│ Question: Is claim within policy limits? │
│ Evidence: Fact C + policy clause 4.6 │
│ Rule: claim_amount ≤ per_event_limit ($2000) │
│ Output: within_limits = TRUE │
│ Escalation: if FALSE → PAUSE (review) │
└──────────────────┬───────────────────────────┘
▼
┌──────────────────────────────────────────────┐
│ NODE 4: FRAUD / ANOMALY CHECK │
│ Question: Does evidence support the claim? │
│ Evidence: Airline notice + hotel invoice + │
│ dates + claim form │
│ Checks: date consistency, document │
│ authenticity signals, amount reasonableness │
│ Output: fraud_score = LOW │
│ Escalation: if MEDIUM/HIGH → DENY + flag │
└──────────────────┬───────────────────────────┘
▼
┌──────────────────────────────────────────────┐
│ DETERMINISTIC EVALUATOR │
│ Required coverage: [1,2,3,4] ALL PASSED │
│ All reason codes collected │
│ All evidence IDs chained │
│ │
│ → APPROVE: $847 reimbursement │
│ → Signed decision record appended │
└──────────────────────────────────────────────┘
Every node produces a signed result with evidence references. The deterministic evaluator doesn’t reason — it checks that all four required nodes passed, collects the reason codes, chains the evidence IDs, and either approves, pauses, or denies. The model never makes the final call.
What the Verifiers Check
After each node produces its proposal:
- Verifier A (Coherence): Given only the clauses and facts provided to Node 2, does “no exclusions triggered” actually follow? Did the model apply clause 4.4 correctly?
- Verifier B (Citation Integrity): Does the model’s reference to “clause 4.6, per-event limit $2,000” actually match what clause 4.6 says in the policy bundle? Is invoice INV-4821 real and does it say $847?
- Verifier C (Completeness): For a travel disruption claim under this policy version and jurisdiction, the required test set is: [coverage, exclusions, limits, fraud]. Have all four run? Did any produce a PAUSE/DENY that wasn’t handled?
Precursor Facts as Signed Artefacts
Notice how the precursor facts are extracted before the decision nodes run. Each one is a signed atomic fact:
{
"fact_id": "PF-001",
"name": "policy_effective_date",
"value": "2025-06-01",
"source_artefact": "POLICY-SCH-7892",
"extraction_method": "deterministic_field_parse",
"signer": "policy_repo_v3.2"
}
{
"fact_id": "PF-002",
"name": "date_of_loss",
"value": "2026-01-15",
"source_artefact": "AIRLINE-NOTICE-QF447",
"extraction_method": "llm_extraction_v2",
"signer": "intake_system",
"verification": "citation_integrity_passed"
}Where possible, extraction is deterministic (parsing structured fields). Where it must be LLM-assisted (messy documents), it’s treated as proposed extraction and the citation integrity verifier runs hard. Either way, downstream nodes consume signed facts, not raw context.
Only Automate the Clean Lanes
Not every decision belongs in a DAG. Automate only where the policy can be expressed as a checklist of necessary/sufficient tests with clear precedence. Treat ambiguous, heavily exception-driven, or adversarially interacting sections as human lanes.
That’s not weakness — that’s how you stop “AI project” from becoming “we accidentally built a legal roulette machine.”
Singapore’s Infocomm Media Development Authority launched the world’s first governance framework specifically for agentic AI in January 2026, recommending that organisations “define limits on an agent’s autonomy and access to data and tools” and “define checkpoints where human approval is required to guard against automation bias.”23 The EU AI Act’s Article 14 embeds a “human-in-command” philosophy requiring that high-risk AI be “designed to allow effective human supervision during use” — not mere human presence, but “meaningful oversight capability.”24
The decision DAG architecture supports both: automated lanes where policy compiles cleanly, with mandatory human checkpoints everywhere else.
The Real Architecture
If you do the design-time work properly, real-time execution becomes mostly orchestration:
- Build the admissible evidence bundle
- Run required precursor fact extractions
- Execute mandated test nodes (some deterministic, some LLM-assisted)
- Collect signed results + reason codes
- Deterministic evaluator checks completeness
- Enforcement boundary gates the action (risk tier, irreversibility, authority level, coverage pass/fail)
- Execute, pause, or escalate
The demo people want — “look, it auto-routes a claim!” — becomes real only when it’s backed by this machinery.
It’s not so much that business people want the smart AI as a magical employee. Maybe we’re pushing more of it back to SDLC and we’re going to write magical software instead.
AI didn’t delete SDLC — it ate SDLC and came back wearing its clothes.
Common Objections
“This is over-engineering. Just use a better model.”
A better model still can’t prove it checked all relevant clauses. Sufficient coverage is a pipeline property, not a model property. Even the most capable model in the world can’t guarantee it considered clause 4.5’s exclusion if clause 4.5 wasn’t in its evidence bundle. The pipeline ensures it was.
“Breaking into micro-judgements loses the holistic view.”
That’s exactly the point. The holistic view is what makes single-verdict approaches ungovernable — you can’t inspect what happened inside a single giant prompt. The deterministic evaluator reconstructs the holistic view from verified components. It sees all four nodes passed, all evidence chains are intact, and sufficient coverage is met. That’s a better holistic view than any single model could provide, because every component has been independently verified.
“This is just regular software engineering.”
Correct. That’s the insight. AI decisions should be governed like software — because software engineering has 50+ years of discipline to draw on. What’s new is that LLMs make this feasible by handling the messy perception layer that made old deterministic systems prohibitively expensive. The deterministic code no longer needs to “understand English” — it just needs to evaluate structured facts. Every time complexity spikes, the answer is “push it back to SDLC.” That’s not retreat. That’s where safety lives.
Your next move: Pick your most complex AI decision. Sketch the DAG. Identify which nodes are necessary, which are disqualifying, and which lack sufficient coverage. You’ll immediately see where the single-verdict approach is hiding governance gaps.
References
- [1]Anthropic Alignment Science. “Reasoning Models Don’t Always Say What They Think.” — “CoTs reveal their usage of hints in at least 1% of examples where they use the hint, but the reveal rate is often below 20%.” arxiv.org/abs/2505.05410
- [2]Anthropic Research. “Reasoning models don’t always say what they think.” — “Claude was faithful 41% of the time and R1 was faithful 19% of the time.” anthropic.com/research/reasoning-models-dont-say-think
- [3]ACL Anthology 2025. “Examining the Faithfulness of Deepseek R1’s Chain-of-Thought.” — “It reports less than 2% of helpful hints… demonstrating a discrepancy between its reported and actual decision process.” aclanthology.org/2025.chomps-main.2.pdf
- [4]ICLR 2026 Submission. “Chain-of-Thought Reasoning In The Wild Is Not Always Faithful.” — “Models sometimes produce superficially coherent arguments to justify systematically answering Yes to both questions or No to both questions.” openreview.net/forum?id=emjPKK11Oo
- [5]AI Safety at the Frontier. “Paper Highlights of November 2025.” — “Penalizing behaviors in outputs caused those behaviors to decrease in CoTs — even when models were clearly still performing the penalized behavior.” aisafetyfrontier.substack.com/p/paper-highlights-of-november-2025
- [6]MIT Technology Review / The Strategy Stack. “Current AI Capabilities and Limitations (2026).” — “Only 20% of AI practitioners believe that their models are fully interpretable.” thestrategystack.substack.com/p/does-ai-behave-like-a-black-hole
- [7]2025 Responsible AI Governance Landscape. “From Principles to Practice.” — “Model-agnostic explainability methods (SHAP, LIME) often provide ‘insufficient detail for regulatory requirements.'” aigl.blog/content/files/2026/02/THE-2025-RESPONSIBLE-AI-GOVERNANCE-LANDSCAPE-FROM-PRINCIPLES-TO-PRACTICE.pdf
- [8]BIS Financial Stability Institute. “Managing explanations: how regulators can address AI explainability.” — “The complexity of certain AI models can make it challenging to explain model outcomes to consumers.” bis.org/fsi/fsipapers24.pdf
- [9]Pixee AI / Enterprise Management Associates. “The Agentic AI Governance Gap.” — “98% of organizations with 500+ employees are deploying agentic AI, yet 79% lack formal security policies.” pixee.ai/blog/agentic-ai-governance-gap-strategic-framework-2026
- [10]Pixee AI / IBM Research. “The Agentic AI Governance Gap.” — “Breaches involving ungoverned ‘shadow AI’ carry a $670,000 cost premium.” pixee.ai/blog/agentic-ai-governance-gap-strategic-framework-2026
- [11]ISACA. “The Growing Challenge of Auditing Agentic AI.” — “Decision-making processes often lack clear traceability… weakening accountability.” isaca.org/resources/news-and-trends/industry-news/2025/the-growing-challenge-of-auditing-agentic-ai
- [12]Tagliabue & Greco. “Safe, Untrusted, ‘Proof-Carrying’ AI Agents.” — “Agents accept or reject pipeline branch merges solely on the basis of verifier outputs, enforcing oracle-driven correctness.” arxiv.org/abs/2510.09567
- [13]Emergent Mind synthesis. “Agentic Proof-Carrying in Data Lakehouses.” — “Only after all correctness properties return True can the agent merge repairs into the production branch.” emergentmind.com/topics/agentic-ai-based-formal-property-generation
- [14]Peng et al. “The Impact of AI on Developer Productivity: Evidence from GitHub Copilot.” — “Developers complete tasks 55–82% faster with AI coding assistance.” arxiv.org/abs/2302.06590
- [15]ISBSG. “Impact of AI-Assisted Development on Productivity and Delivery Speed.” — “48x acceleration in model development; reducing months to days.” isbsg.org/wp-content/uploads/2026/02/Short-Paper-2026-02-Impact-of-AI-Assisted-Development-on-Productivity-and-Delivery-Speed.pdf
- [16]Dreamztech / Gartner Research. “How AI Is Transforming Custom Software Development in 2026.” — “AI-augmented development teams deliver 2.3x more features per quarter compared to 2023 baselines.” dreamztech.com/blog/ai-transforming-custom-software-development-2026/
- [17]Nature / Scientific Reports. “Temporal quality degradation in AI models.” — “91% of ML models experience degradation over time.” nature.com/articles/s41598-022-15245-z
- [18]Open Policy Agent. “OPA Official Documentation.” — “OPA decouples policy decision-making from policy enforcement… evaluates the query input against policies and data.” openpolicyagent.org/docs
- [19]NexaStack. “Agent Governance at Scale: Policy-as-Code Approaches.” — “Organisations adopting Policy-as-Code typically see a 40–70% reduction in compliance costs.” nexastack.ai/blog/agent-governance-at-scale
- [20]NexaStack. “Agent Governance at Scale.” — “Policy-as-Code systems evaluate decisions before execution — blocking violations in real time.” nexastack.ai/blog/agent-governance-at-scale
- [21]Regure / Forrester. “The State of Claims Automation in 2026.” — “91% of insurance organizations report they will have AI-powered claims automation deployed in production by end of 2026.” getregure.com/blog/claims-automation-trends-2026/
- [22]Enlyte. “Navigating AI and Claim Handling in 2026.” — “Florida’s HB 527 explicitly prohibits using an algorithm or AI system as the sole basis for denying or reducing a claim payment.” enlyte.com/insights/article/compliance/ai-claims-handling-compliance-2026
- [23]Baker McKenzie / BIIA. “Singapore: Governance Framework for Agentic AI Launched.” — “The world’s first governance framework specifically designed for AI agents capable of autonomous planning, reasoning and action.” bakermckenzie.com/en/insight/publications/2026/01/singapore-governance-framework-for-agentic-ai-launched
- [24]Secure Privacy. “EU AI Act 2026 Compliance Guide.” — “Article 14 embeds a ‘human-in-command’ philosophy requiring that high-risk AI be designed to allow effective human supervision during use.” secureprivacy.ai/blog/eu-ai-act-2026-compliance
Scott Farrell helps Australian mid-market leadership teams ($20M–$500M revenue) turn scattered AI experiments into a governed portfolio that compounds EBIT and reduces risk. leverageai.com.au
Discover more from Leverage AI for your business
Subscribe to get the latest posts sent to your email.